
이전 글 연계
[SQL] 데이터분석의 꽃, GROUP BY(~HAVING, DESC)
정말 핵심적인 문법이다 꽃이라고 불릴 만큼 중요하게 보는 부분이 바로 이 GROUP BY이지만 위에 보이는 것처럼 예쁜 꽃이 될 수도, 예쁘지만 가시가 달린 장미가 될 수도 있다 그만큼 중요하고,
time-map-installer.tistory.com
[SQL] 데이터분석의 농경지, CREATE TABLE
그동안 우리는 만들어져있는 데이터베이스를 통해 데이터를 찾고, 분류하는 활동들을 해 왔다 이번에는 우리가 그 많은 데이터를 이용해 검색을 할 수 있었던 근본, TABLE을 생성/삭제하는 방법
time-map-installer.tistory.com
이론을 통해 GROUP BY ~ CREATE TABLE까지 알아보았다면 이제는 실습을 통해 기억에 남겨 볼 차례이다
오늘도 준비가 되었다면 아래 경계선을 넘어가 시작해보도록 하자
GROUP BY PART
HINT!
오류가 났다면 GROUP BY로 선택한 항목 외의 것들을 보고
집계함수가 있는 지 없는 지 확인해보자
WHERE 뒤에 집계함수의 조건문을 쓴 것은 아닌 지 확인해보자
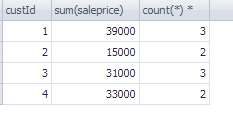
1. custId를 Orders에서 불러와 custId와 saleprice의 합, 각 항목별 전체합으로 묶어보자
힌트 보기
GROUP BY
SUM
COUNT
정답 보기
SELECT custId, sum(saleprice), count(*)
FROM Orders
GROUP BY custId;
2. 가격이 8000원 이상인 도서를 구매한 고객에 대하여 고객별 주문 도서의 총 수량을 구하시오
힌트 보기
GROUP BY
WHERE
HAVING
SUM
COUNT
정답 보기
SELECT custid, COUNT(*)
FROM Orders
WHERE saleprice >= 8000
GROUP BY custid
HAVING COUNT(*) >= 2;

3. 고객ID를 역순으로, saleprice의 합계를 출력해보시오
힌트 보기
DESC
GROUP BY
SUM
정답 보기
SELECT custid, sum(saleprice)
FROM Orders
GROUP BY custid
ORDER BY 1 DESC;

4. 도서번호 별 구매한 사용자가 몇 명인지 구하시오(중복없음)
힌트 보기
DISTINCT
GROUP BY
COUNT
정답 보기
SELECT bookid, count(distinct(custid))
FROM Orders
GROUP BY bookid;

5. 구매가격 총 합이 10000원이 넘는 고객 중 id가 5번 이하인 고객을 구하시오
힌트 보기
GROUP BY
WHERE
SUM
HAVING
정답 보기
SELECT custid, SUM(saleprice)
FROM Orders
WHERE orderid <= 5
GROUP BY custid
HAVING SUM(saleprice) > 10000;

CREATE TABLE PART
HINT!
생성할 때 FOREIGN KEY 지정해두기
데이터타입을 잘못 설정한 것은 아닌가 확인해보기
1. NewBook이라는 TABLE을 생성해보시오
- integer형 bookid(FOREIGN KEY)
- VARCHAR(20)형 bookname
- VARCHAR(20)형 publisher
- integer형 price
힌트 보기
CREATE TABLE
PRIMARY KEY()
정답 보기
CREATE TABLE NewBook(
bookid INTEGER,
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER,
PRIMARY KEY(bookid));

2. 다음 SQL문을 보고 어디서 에러가 발생할 지에 대해 설명해보시오(위에서 생성된 NewBook참조)
- INSERT INTO NewBook VALUES(1, 'book1', 'timesquare', 100000);
- INSERT INTO NewBook VALUES(1, 'book2', 'times', 150000);
힌트 보기
책이름이 성의없어서는 아니다
정답 보기
PRIMARY KEY로 지정한 boookid는 중복되어서는 안된다

3. NewBook이라는 TABLE을 지우고 아래와 같이 생성해보시오
- Null값이 들어가지 않는 VARCHAR(20)형태의 bookname
- 같은 이름이 아니어야 하는 VARCHAR(20)형태의 publisher
- 1000원보다 클 경우 기본값인 10000원으로 바꾸어주는 integer형태의 price
- PK는 bookname과 publisher을 동시에 사용한다
힌트 보기
정답 보기
DROP TABLE NewBook;
CREATE TABLE NewBook(
bookname VARCHAR(20) NOT NULL,
publisher VARCHAR(20) UNIQUE,
price INTEGER DEFAULT 10000 CHECK(price > 1000),
PRIMARY KEY(bookname, publisher));

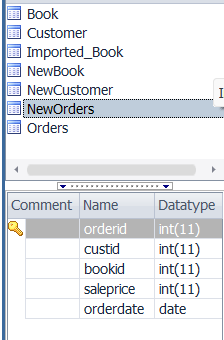
4. NewOrders라는 TABLE을 생성해보시오
- integer형 custid(PK)
- VARCHAR(40)형 name
- VARCHAR(40)형 address
- VARCHAR(30)형 phone
힌트 보기
정답 보기
CREATE TABLE NewCustomer(
custid INTEGER,
name VARCHAR(40),
address VARCHAR(40),
phone VARCHAR(30),
PRIMARY KEY (custid));

5. NewCustomer이라는 TABLE을 생성해보시오
- integer형 custid(PK)
- VARCHAR(40)형 name
- VARCHAR(40)형 address
- VARCHAR(30)형 phone
힌트 보기
정답 보기
CREATE TABLE NewCustomer(
custid INTEGER,
name VARCHAR(40),
address VARCHAR(40),
phone VARCHAR(30),
PRIMARY KEY (custid));
6. NewOrders라는 TABLE을 생성해보시오
- integer형 orderid(PK)
- Null값이 들어가지 않는 integer형태의 custid
- Null값이 들어가지 않는 integer형태의 bookid
- integer형 saleprice
- date형태의 orderdate
- custid를 NewCustomer의 custid에서 참조하고 연쇄 삭제
힌트 보기
CREATE NUD
REFERENCES
FOREIGN KEY
ON DELETE CASCADE
정답 보기
CREATE TABLE NewOrders(
orderid INTEGER,
custid INTEGER NOT NULL ,
bookid INTEGER NOT NULL,
saleprice INTEGER,
orderdate DATE,
PRIMARY KEY (orderid),
FOREIGN KEY (custid) REFERENCES NewCustomer(custid)
ON DELETE CASCADE);
잘 풀어냈다면 SQL에 대한 지식이 크게 늘었다고 생각해도 될 정도로 훌륭한 성과를 이루었다고 볼 수 있다
고생 많으셨습니다
'Development Study > Backend' 카테고리의 다른 글
| [SQL] 실습 정리(+JOIN, OUTER_JOIN, CASE, SUBQUARY) (0) | 2022.11.12 |
|---|---|
| [SQL] JOIN문 실습 정리 (0) | 2022.11.11 |
| [SQL] 데이터분석의 농경지, CREATE TABLE (0) | 2022.10.20 |
| [SQL] 데이터분석의 꽃, GROUP BY(~HAVING, DESC) (0) | 2022.10.20 |
| [SQL] 일주일 뒤에 풀어보는 SQL ( SELECT함수 ~ 집계 함수 ) (2) | 2022.10.14 |