
그동안 우리는 만들어져있는 데이터베이스를 통해 데이터를 찾고, 분류하는 활동들을 해 왔다
이번에는 우리가 그 많은 데이터를 이용해 검색을 할 수 있었던 근본,
TABLE을 생성/삭제하는 방법에 대해 알아보도록 하겠다
지금 저는 TABLE보다는 데이터를 조작해보고 싶어요!
[SQL] 데이터분석의 꽃, GROUP BY(~HAVING, DESC)
정말 핵심적인 문법이다 꽃이라고 불릴 만큼 중요하게 보는 부분이 바로 이 GROUP BY이지만 위에 보이는 것처럼 예쁜 꽃이 될 수도, 예쁘지만 가시가 달린 장미가 될 수도 있다 그만큼 중요하고,
time-map-installer.tistory.com
중복되면 안되는 KEY - PRIMARY KEY
우리가 살아가면서 이름이 같아 곤란한 경험을 한 적이 몇 번은 있을 것이다
분명 내 이름을 불렀는데? 내가 아니네??
이렇게 같은 이름을 쓰는 사람들끼리 상당히 곤란한 상황에 처해있을 때가 많다
사실 이름을 모두 다르게 하면 해결되는 문제이지만
어떻게 그 많은 사람들에게 다른 이름을 지어줄 수 있겠는가?

그래서 우리나라의 경우엔 이름은 같아도 다른 사람인 것을 증명하기 위한 주민등록번호제도가 있다
데이터도 마찬가지이다
분명 내가 원하는 것은 이게 아닌데 이름이 같다는 이유로
계속해서 함께 불러와지면 얼마나 복잡할까
특히 데이터베이스의 크기가 커지면 커질 수록 더 하다는 것
이러한 상황을 방지하기 위해 데이터를 생성할 때 PRIMARY KEY를 이용한다
PRIMARY KEY를 지정하는 방법 - CREATE
PRIMARY KEY를 지정하려면 CREATE문을 알아야 할 것이다
그렇다면 CREATE문은 어떻게 작성할까?
우리는 NewBook이라는 새 테이블을 만들어 볼 것이다
CREATE TABLE NewBook(
bookid INTEGER,
bookname VARCHAR(20),
publisher VARCHAR(20),
price INTEGER,
PRIMARY KEY(bookid));
제일 아래 줄에 PRIMARY KEY(지정하려는 칼럼명)으로 입력하면 PRIMARY KEY를 생성한다
PRIMARY KEY는 여러 개를 동시에 지정해서 구분할 수도 있다(책이름+출판사 등)


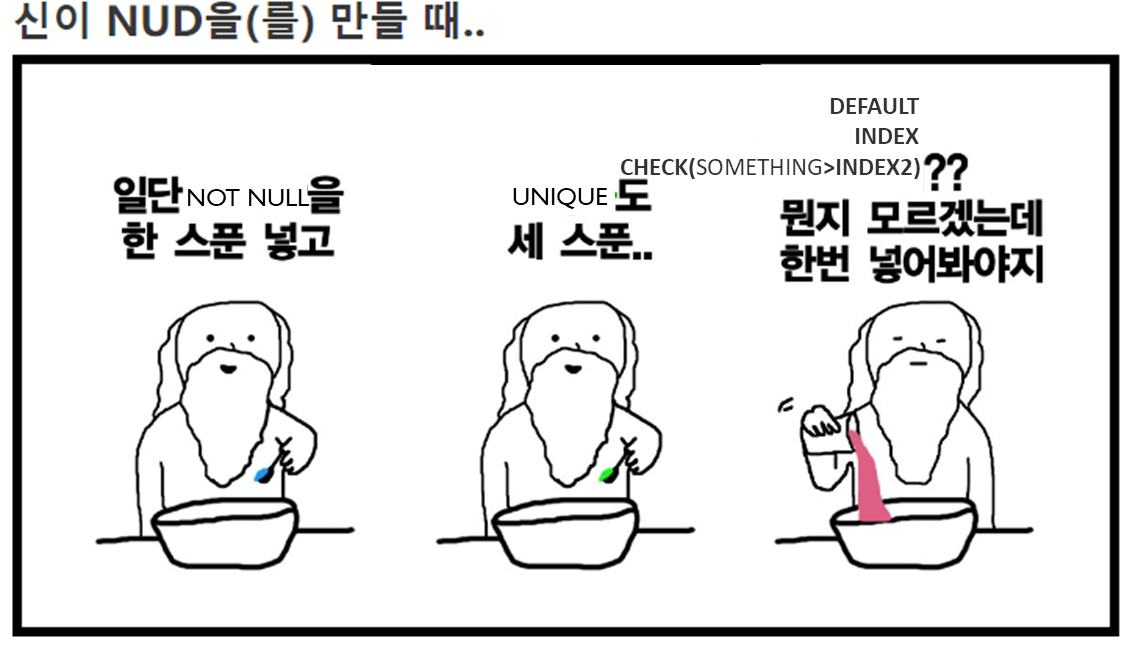
생성할 때 조건이 있어 - CREATE NUD
크리에이트 너드
라고 불리는 조건이 있다(작성자가 만듬)
테이블을 생성할 때 여러 조건들을 붙여줄 수 있는데
NOT NULL
UNIQUE
DEFAULT (조건문 위배 시 결과값) CHECK(조건문)
위 세 가지를 통해 추가적인 조건을 붙일 수 있다
그래서 이런 조건을 붙여서 데이터 테이블을 다시 만들어보자면?
CREATE TABLE NewBook(
bookname VARCHAR(20) NOT NULL,
publisher VARCHAR(20) UNIQUE,
price INTEGER DEFAULT INDEX CHECK(SOMETHING > INDEX1),
PRIMARY KEY(bookname, publisher));
NOT NULL
- NULL값이 되지 않게 한다
UNIQUE
- 중복된 키가 들어오지 않도록 한다
DEFAULT INDEX CHECK(SOMETHING>INDEX2)
- SOMETHING이 INDEX2 보다 클 경우만 입력되게 하고 값이 입력되지 않았을 때 INDEX값으로 바꾸어준다
만약 KEY값을 타 테이블에서 참조하고 싶다면??
PRIMARY KEY 아래에 다음과 같이 작성하면 된다
FOREIGN KEY (칼럼명) REFERENCES 테이블명(칼럼명)
이 때, 두 칼럼명은 같게 해둔다
만들어둔 TABLE에 씨앗 심기 - INSERT INTO ( ) VALUES
위에서는 TABLE을 만드는 작업을 하였다
그렇다면 우리는 TABLE에 데이터를 추가할 차례이다
INSERT INTO를 이용하여 데이터를 추가할 수 있는데 이 때, 주의할 사항이 몇 가지 있다
- PRIMARY KEY에 NULL값 OR 중복되는 값 넣지 않기
- TABLE을 생성할 때 지정해둔 DATA TYPE 위반하지 않기
위 사항을 위배하지 않고 위에 NewBook에 데이터를 추가해보자
INSERT INTO NewBook VALUES(1, 'book1', 'lifeIsGood', 100000);

데이터 삭제 - DROP, ON DELETE CASCADE
실습에서 자주 TABLE을 만들고 지울 때 쓰이는 CREATE와 DROP,
실무에서 절대 쓰이지 말아야 할 DROP은
간단하게도
DROP TABLE 테이블명
이 한줄로 실행이 된다
혼자 연습할 때는 사용하되, 절대 실무에서 사용하지 말자
상당한 혼란을 야기할 수 있다(물론 권한이 없어 사용하지는 못하겠지만)
테이블의 구조를 내버려두고 데이터를 갈아버려야 할 때는
DROP TABLE 대신에
ON DELETE CASCADE를 이용해 틀 안의 데이터만 날려보자

되짚어보기 - CREATE = DDL
잠깐!
DDL이 기억 안나신다면?
[GoormIDE] 데이터를 관리해보자 - 1 (컨테이너 생성)
데이터관리, SQL이용해 데이터를 다루는 이 과목은 기초적인 SQL문을 이용해 데이터를 자유자재로 검색하고 조작하고 심지어는 설계까지 하는 경지를 바라보며 듣는 과목이 아니라 해도 과언이
time-map-installer.tistory.com
정말 오랜만에 보는 글이다
잠시 초심을 찾아보는 것도 괜찮지 않을까?
CREATE가 DDL이라는 사실이 기억났다면 SQL에 대한 공부가 잘 되었다고 생각하면 될 것이다
기억이 안났어도 다시 보면 기억날 것이다
걱정할 필요는 없다
'Development Study > Backend' 카테고리의 다른 글
| [SQL] JOIN문 실습 정리 (0) | 2022.11.11 |
|---|---|
| [SQL] 연습 문제 ( GROUP BY ~ CREATE ) (0) | 2022.10.20 |
| [SQL] 데이터분석의 꽃, GROUP BY(~HAVING, DESC) (0) | 2022.10.20 |
| [SQL] 일주일 뒤에 풀어보는 SQL ( SELECT함수 ~ 집계 함수 ) (2) | 2022.10.14 |
| [SQL] 연습 문제 ( SELECT함수 ~ 집계 함수 ) (0) | 2022.10.08 |