Type: 데이터 수집 / 분석
주제: Web Crawling
사용 IDE: IntelliJ IDEA
사용 언어: Python
사용 패키지: bs4 - BeautifulSoup, requests - get
GitHub Link: https://github.com/TMInstaller/WebCrawling_Myblog
이전 편 보고 오기
[WebCrawling] 내 블로그의 정보를 직접 분석해보자 -1편
Type: 데이터 수집 / 분석 주제: Web Crawling 사용 IDE: IntelliJ IDEA 사용 언어: Python 사용 패키지: bs4 - BeautifulSoup, requests - get GitHub Link: https://github.com/TMInstaller/WebCrawling_Myblog 더보기 GitHub - TMInstaller/WebCraw
time-map-installer.tistory.com
설계 - 어떤 기능을 추가할까?
이번 편의 목표는 다음과 같다
목표: 메인 화면이 아니라 특정 키워드를 검색했을 때 나오는 결과에 대한 정보를 수집해보자

코드 작성
1. 검색할 때 나타나는 블로그의 url 가져오기
2. 개발자 모드를 통해 살펴본 위치의 정보 저장
3. 2번에서 더 세부적인 위치를 찾아서 저장
4. 가장 세부적인 위치를 찾아서 출력해보기
1. 검색 할 때 나타나는 블로그의 url 가져오기
url = "https://time-map-installer.tistory.com/search/"
keyword = "Python"
response = get(f"{url}{keyword}")
Python을 검색했을 때 다음과 같이 나타나므로 코드를 위와 같이 작성해준다
f"{변수명}{변수명}" = "값+값" 이므로 합쳐진 url을 변수에 저장한다
2. 개발자 모드를 통해 살펴본 위치의 정보 저장
# else:
soup = BeautifulSoup(response.text, 'html.parser')
keys = soup.find_all('div', class_='inner')class가 inner인 div의 정보를 가져올 것이기에 위와 같이 작성하였다

3. 2번에서 더 세부적인 위치를 찾아서 저장
# key_posts = key_section.find_all('div', class_='post-item')
for post in key_posts:
span = post.find('a')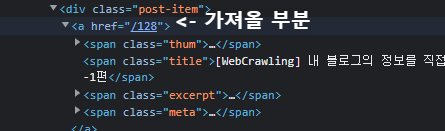
4. 가장 세부적인 위치를 찾아서 출력해보기
# for post in key_posts:
# span = post.find('a')
thum = span.find('span', class_='thum')
title = span.find('span', class_='title')
excerpt = span.find('span', class_='excerpt')
meta = span.find('span', class_='meta')
print(thum, title, excerpt, meta)
print('//////////////////')
0. 전체 코드 / 실행 결과
# main.py
from requests import get
from bs4 import BeautifulSoup
# 검색 시 작동 하는 url link 가져오기
url = "https://time-map-installer.tistory.com/search/"
# 검색 시 입력 될 키워드 입력하기
keyword = "Python"
# 두 값을 합쳐 검색 시 나오는 url link 설정하기
response = get(f"{url}{keyword}")
if response.status_code != 200:
print("페이지를 불러올 수 없습니다", response.status_code)
else:
soup = BeautifulSoup(response.text, 'html.parser')
# 찾을 정보를 keys 변수에 새로 저장
keys = soup.find_all('div', class_='inner')
for key_section in keys:
# key posts에 div 태그의 post-item들만 불러오기 위한 준비
key_posts = key_section.find_all('div', class_='post-item')
for post in key_posts:
# 그 안에서 a 태그 안의 모든 것을 가져올 준비
# a 태그가 하나라 find_all 대신 find 사용
span = post.find('a')
# a 태그 안에 각각의 태그들이 하나씩이면 find, 여러개면 find_all로 불러오기
thum = span.find('span', class_='thum')
title = span.find('span', class_='title')
excerpt = span.find('span', class_='excerpt')
meta = span.find('span', class_='meta')
# 출력하고 구분자로 나눠보기
print(thum, title, excerpt, meta)
print('//////////////////')주석을 달아 둔 전체 코드와 실행결과이다

다음 편에서 계속됩니다
'활동내역.zip > 개인' 카테고리의 다른 글
| [WebCrawling] 웹사이트를 직접 분석해보자 -4편 (0) | 2022.12.05 |
|---|---|
| [WebCrawling] 웹사이트를 직접 분석해보자 -3편 (0) | 2022.12.05 |
| [WebCrawling] 웹사이트를 직접 분석해보자 -1편 (0) | 2022.12.04 |
| [HTML+CSS] 무작정 따라 만들어보기(쿠팡 footer만들기 2편) (0) | 2022.11.20 |
| [HTML+CSS] 무작정 따라 만들어보기(쿠팡 footer만들기 1편) (0) | 2022.11.20 |